Introduction
This white paper explores the efficacy of large language models (LLMs) in analyzing email communications regarding satellite conjunctions. Email remains a primary method of coordination for conjunction events in the aerospace industry, despite the existence of automated services such as SpaceTrack, Celestrak, and Starlink's Space Traffic Coordination APIs.
The aerospace sector is traditionally slow to adopt new technologies due to its low tolerance for risk and uncertainty. As such, studies such as this are essential to building trust and understanding within the aerospace community regarding the efficacy of application of LLMs in automated solutions.
Background
Space traffic management is significantly less structured compared to air traffic control, lacking standardized interfaces and scalable coordination frameworks. Most satellite conjunction coordination occurs through email communications among interested parties. Given the text-based nature of these exchanges, LLMs provide an opportunity to improve efficiency and reliability in two key areas:
- Classification: Identifying whether an email pertains to an upcoming satellite conjunction.
- Extraction: Extracting satellite identifiers from emails concerning conjunction events.
These areas highlight the need to assess the capabilities of LLMs in automating email processing tasks and evaluating their current performance.
Methodology
Dataset Construction
To evaluate these applications, a synthetic dataset of emails was created, attempting to capture much of the diversity seen in actual spacecraft operation scenarios. The dataset consists of two parts:
Classification Dataset:
The classification dataset consisted of 200 emails. A subset of 100 emails were about conjunctions (expected to be classified as True), whereas the remaining subset of 100 emails were not about conjunctions (expected to be classified as False).
Extraction Dataset:
A total of 1000 emails were proposed for the extraction dataset, created by varying satellite identifiers across 100 template emails. From this set of 1000 emails, three categories of extraction scenarios were defined based on the number of objects available for extraction in each email..
- Zero Objects Case: Emails with no satellite identifiers (10 samples)
- One Object Case: Emails with only one satellite identifier (40 samples)
- Two Objects Case: Emails containing both satellite identifiers (950 samples)
For more information, the dataset used for this white paper is publicly available on Hugging Face.
Language Models Evaluated
This study tested a variety of LLMs across different parameter sizes, architectures, and providers. The models evaluated span parameter sizes from 8 billion parameters to some of the largest cutting-edge models. A range of different model architectures were explored, including traditional transformer models, reasoning-optimized models, and mixture-of-experts models. Additionally, both open and closed source models were evaluated, as the ability to deploy models on-premises versus being required to communicate over API is a key consideration for applications in the aerospace industry. This diversity was intended to help identify key performance differentiators for selecting a LLM-based solution.
The overall list of LLMs evaluated includes:
gemini-2.0-flash, deepseek-r1-distill-llama-70b, gemma2-9b-it, llama-3.1-8b-instant, llama-3.3-70b-versatile, mixtral-8x7b-32768, gpt-4o-mini, and o1-mini.
Prompting Strategy
Two standardized prompts were used without any fine-tuning.
The prompt used for classification inference queries was as follows:
Analyze the following email delimited by ###. Does the email discuss a potential collision, conjunction, or close approach event between two satellites? Answer with exactly one word: 'yes' or 'no'.### {EMAIL} ###The prompt used for extraction inference queries was as follows:
Analyze the following email delimited by ###. Extract only the identifiers for the satellites that are involved in a potential collision, conjunction, or close approach event. Provide your answer as a comma-separated list of satellite identifiers with no additional text. If no satellite identifiers are found, reply with 'None'.### {EMAIL} ###Grading Paradigm
In both the classification and extraction cases, post processing routines were applied to standardize provided results. This included removing unnecessary characters and whitespace (e.g., parentheses, brackets, hash symbols), forcing lowering of capitalization, and other simple string manipulation techniques.
In the classification datasets, the resulting string was evaluated to detect a single yes, or no answer. If both cases were detected in the result, the case was marked as a failure.
In the extraction datasets, each satellite may be referred to by more than one identifier, and only one identifier for each object was required to be considered a pass. Reporting more than one identifier for either object was considered a pass as long as both objects were detected. Extraneous identifiers not related to either object or an object missing any identifier entirely were considered fails. No partial grades were allowed.
Limitations
While this study provides valuable insights into the application of LLMs for satellite conjunction email processing, several limitations should be noted. First, the dataset proposed in this white paper was synthetic and may not fully capture the nuances and variations found in real-world email communications. The models and prompts were not optimized, relying on default temperature settings and no system prompt tuning, all of which could be investigated in future studies to improve performance. This study did not assess latency or cost, both of which are important considerations for real-world deployment and operational feasibility.
Results
Classification Performance
The first step in analyzing the classification results is to look at the confusion matrix metrics across all of the models.
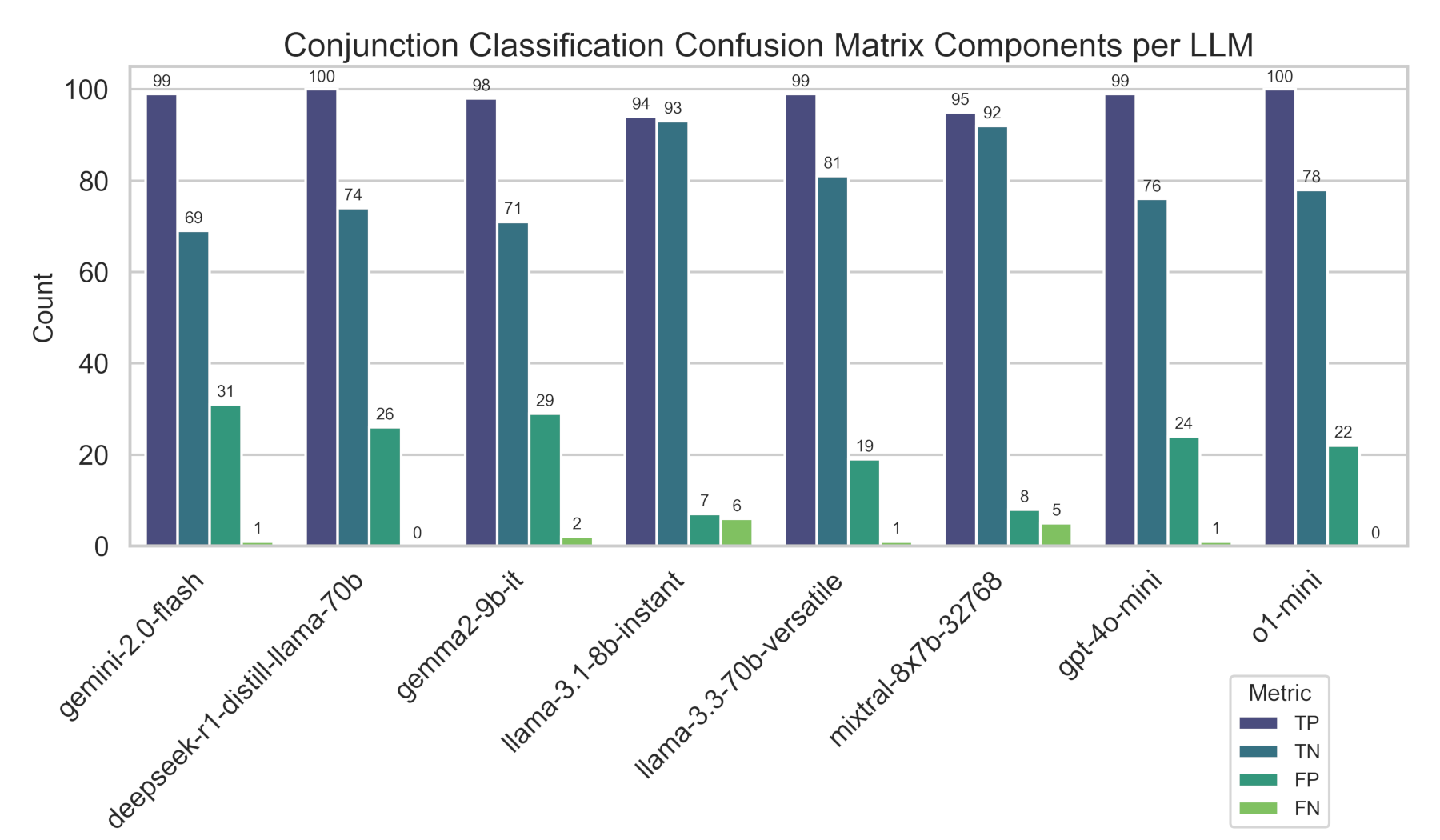
Classification performance was strong, with only marginal differences in accuracy detected between model sizes and architectures. True positive accuracy ranged from 94% to 100%, ensuring a high reliability in effectively identifying conjunction related emails. False negatives ranged from 0% to 6% in the worst case, which is a critical metric to track for safety-sensitive applications. The primary challenge was differentiating emails that did not contain conjunction discussions (false positives), which ranged anywhere from 7% to 31% of cases. Finally, true negative results ranged from 69% to 93%, indicating that some models may incorrectly classify emails unrelated to conjunctions as if they were about conjunctions.
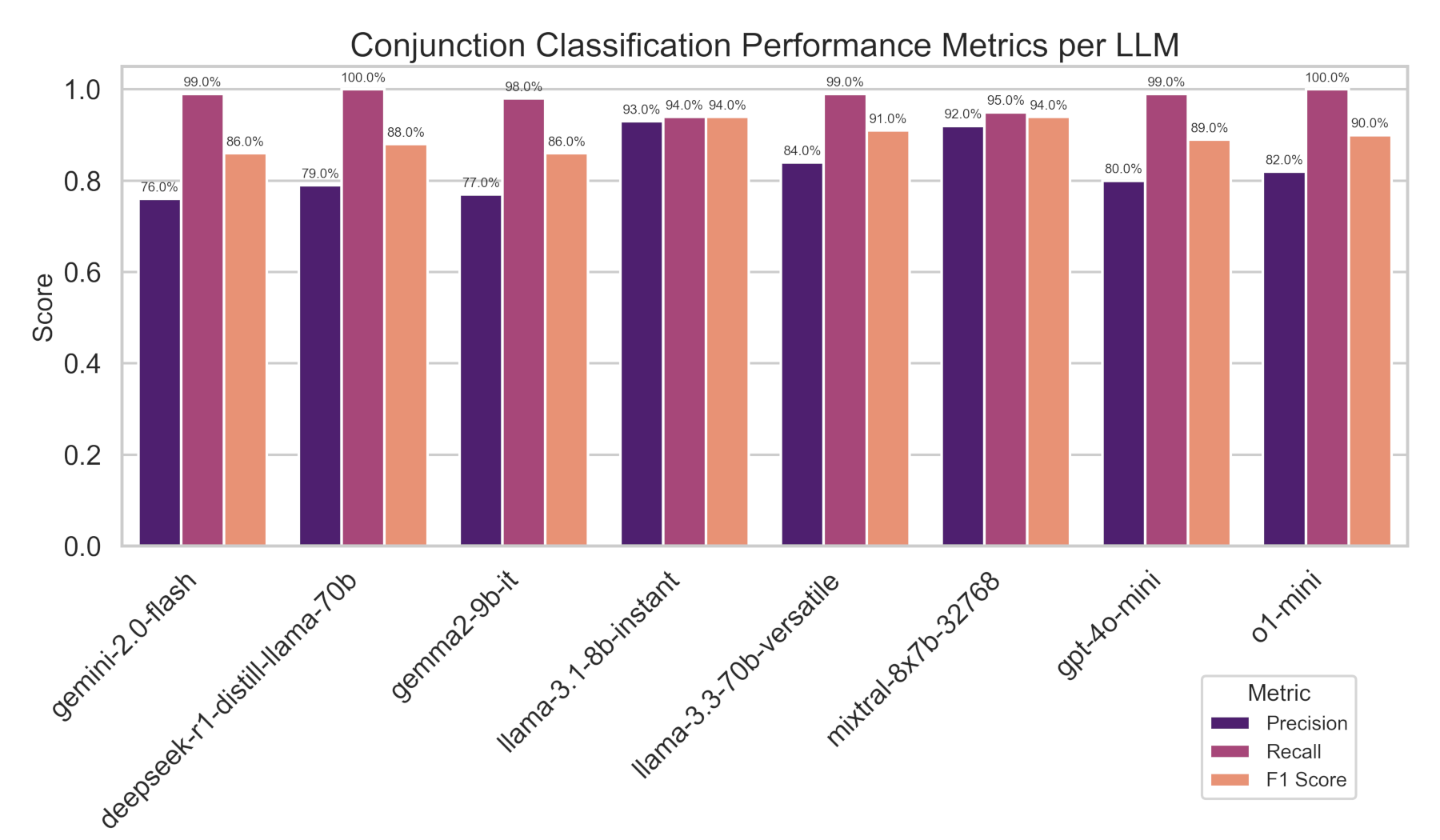
Analyzing precision, recall, and F1 score more specifically, we see recall consistently outperformed precision, indicating that LLMs prioritize detecting conjunction-related emails over avoiding false positives. Some models were able to achieve 100% precision and over 90% F1 scores.
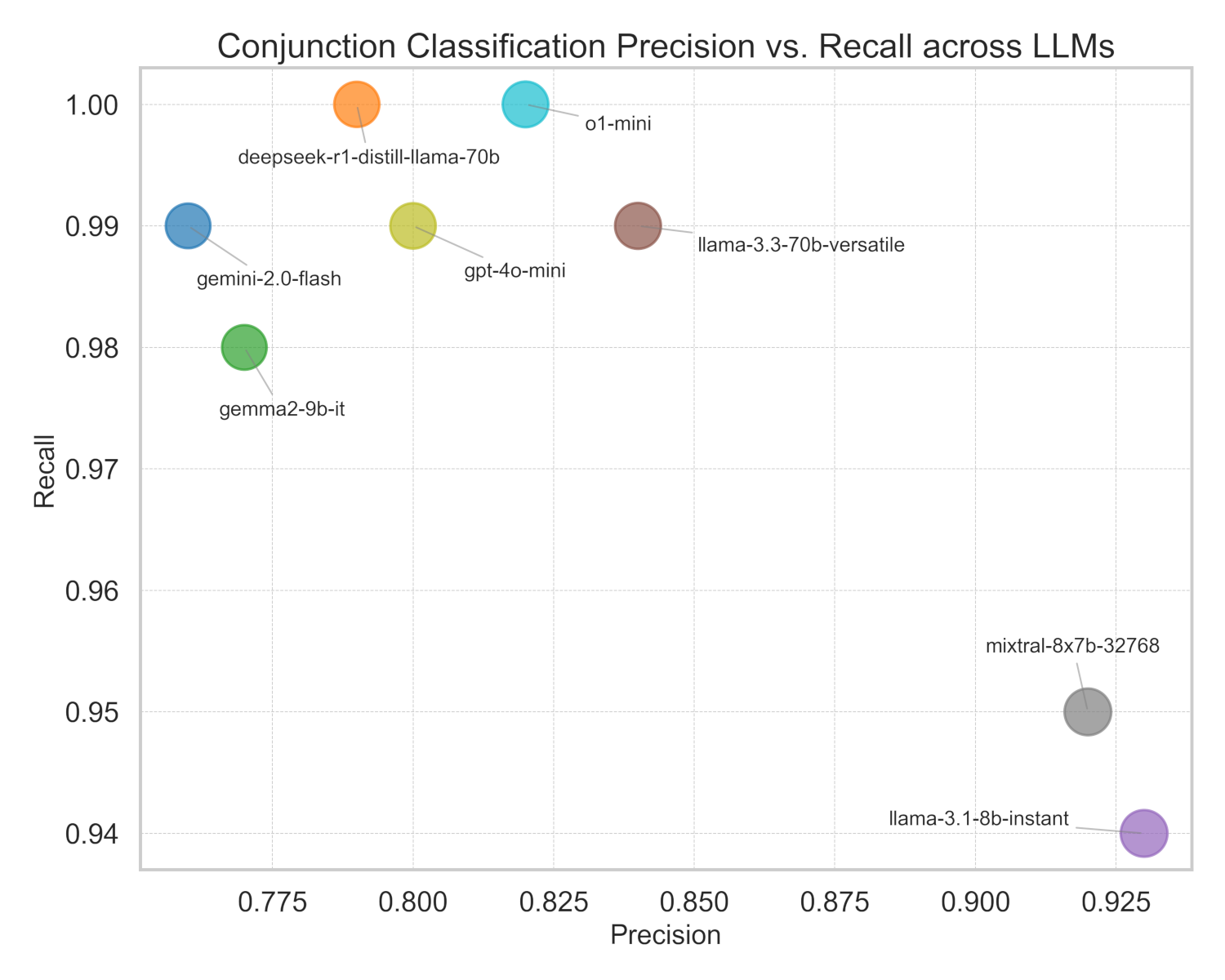
Putting these results together in a scatter plot allows us to analyze a Pareto front in order to select recommended models.
From this analysis the recommendation for an API-based solution would be to go with OpenAI's o1-mini model based on its demonstrated very high recall score. If on-premises solutions are required, Meta’s llama-3.3-70b-versatile model offers a competitive solution, with improved precision at a small cost to recall.
Extraction Performance
The first step in analyzing extraction performance is to examine overall accuracy across all models.
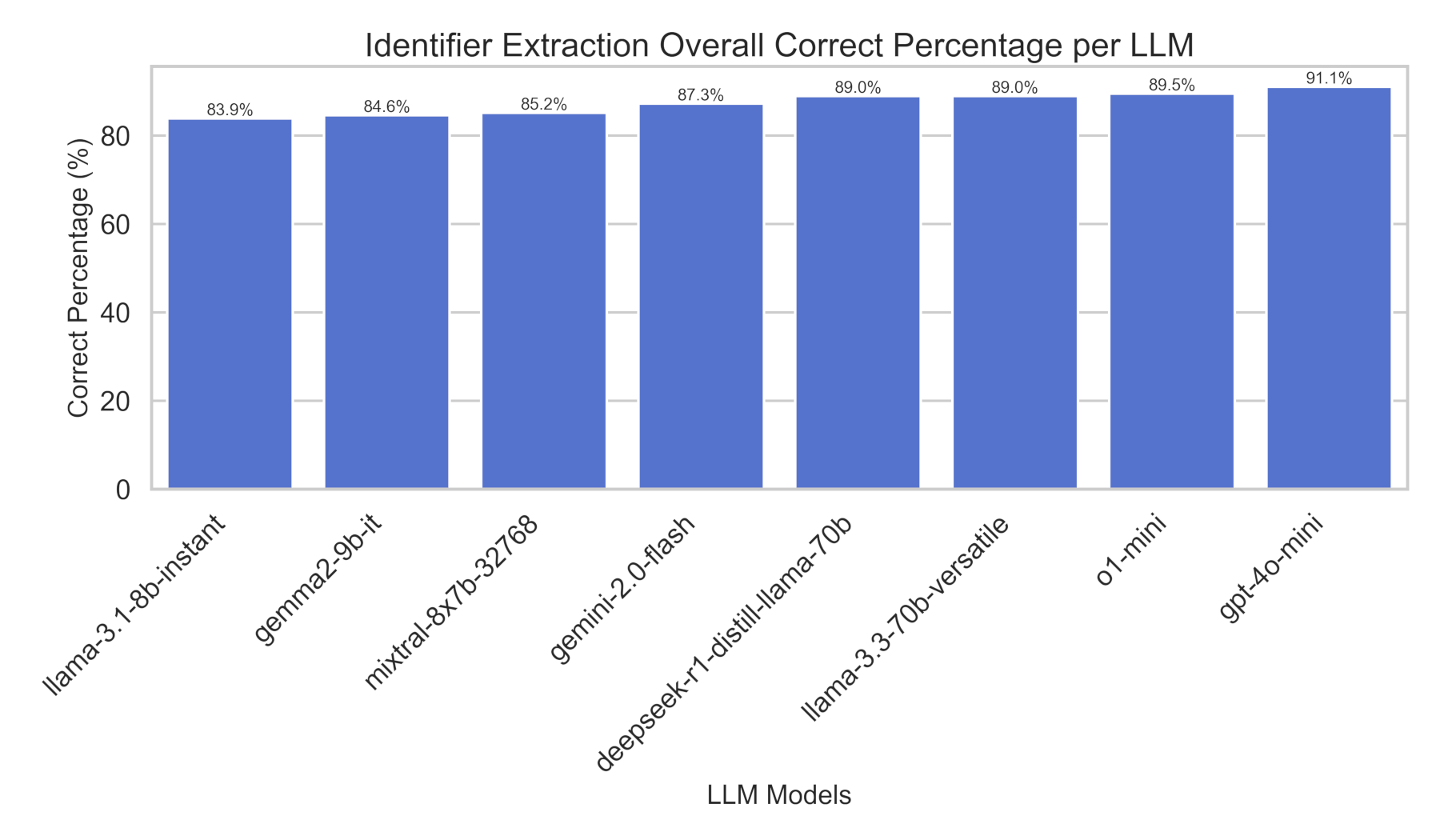
Extraction accuracy was strong across all tested models, ranging from 83.9% (llama-3.1-8b-instant) to 91.1% (gpt-4o-mini). However, more insights can be extracted by analyzing these results on a per case basis.
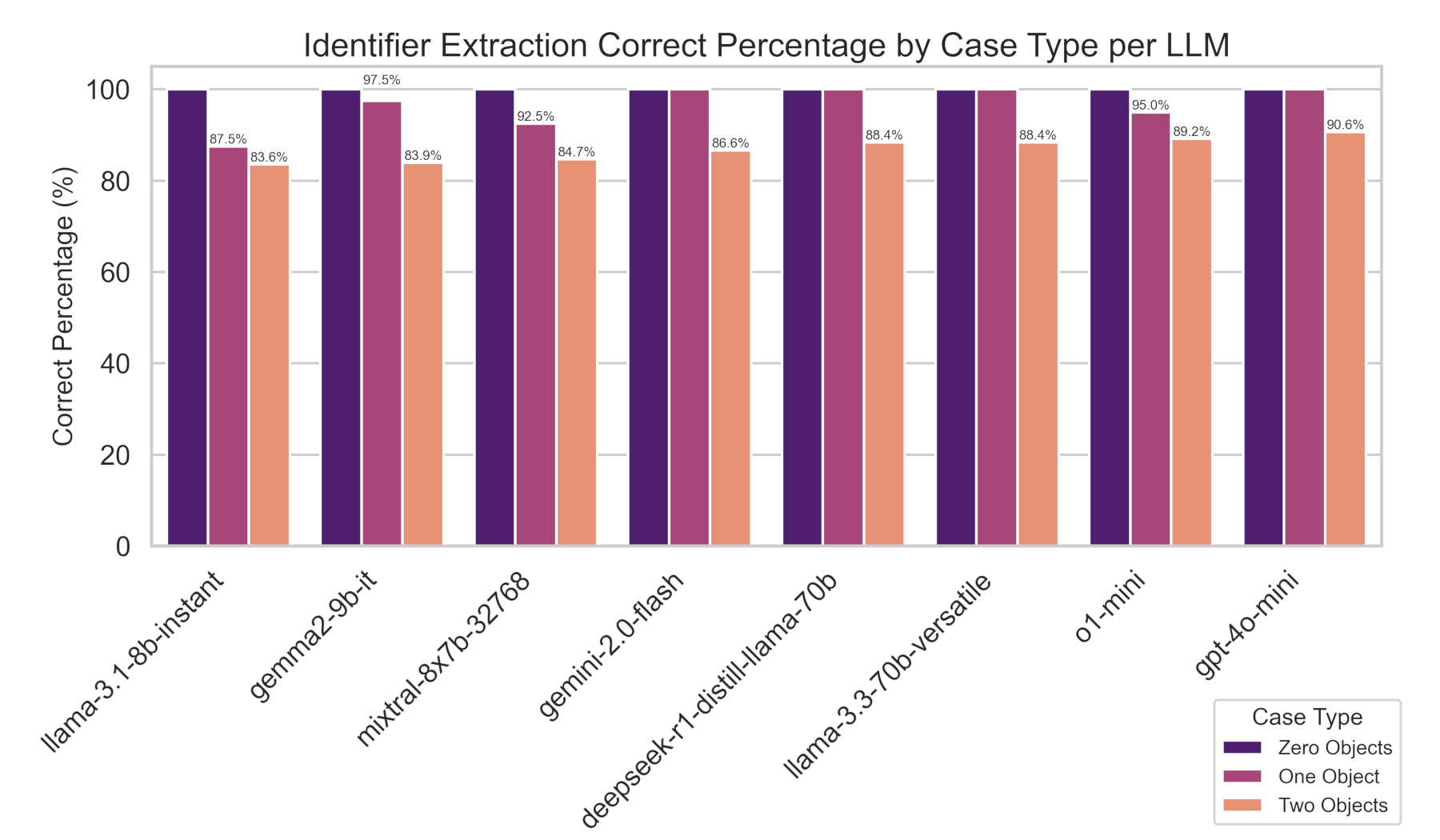
Breaking down performance by case complexity, in the Zero Objects Case, all models achieved 100% correct percentage, demonstrating strong baseline performance.
In the One Object Case, we begin to see declines in performance across some models, but many maintain their 100% correct percentage.
The Two Objects Case is where we start to see more significant declines in scores across all models, where gpt-4o-mini remained the top performer at 90.6%.
While performance was generally high, scores trended negative as the number of identifiers in an email increased, indicating a greater challenge in parsing complex cases.
Putting these results together, gpt-4o-mini is the recommended model for an API-based extraction solution due to its leading performance across all cases. For on-premises deployment, llama-3.3-70b-versatile offers a strong alternative with competitive accuracy.
Conclusion
This study provides a baseline evaluation of LLMs in satellite conjunction email analysis, highlighting their potential as automated solutions for text-based coordination. Through standardized testing, we have identified models that excel in both identifying conjunction-related emails and extracting satellite identifiers with high accuracy. For organizations with the ability to use cloud-based solutions, the preferred combination is o1-mini for classification and gpt-4o-mini for extraction. Organizations requiring on-premises solutions may find llama-3.3-70b-versatile to be the preferred model, as it demonstrated consistently strong performance across both classification and extraction tasks.
While these results offer a strong starting point, future research can explore prompt optimization, fine-tuning, and additional pre- and post-processing techniques to further improve performance. As LLM technology continues to evolve, new advancements may yield even better results, making it essential for stakeholders in satellite operations to stay updated with the latest developments.