Abstract
This whitepaper presents an evaluation of large language models (LLMs) in assessing the consistency of engineering requirements for a fictional spacecraft. The study focuses on five critical subsystems—propulsion, power, thermal, communications, and attitude determination and control—each represented by 10 distinct requirements. For each requirement, a total of four synthetic bodies of text were generated, two representing consistent cases and two representing inconsistent cases with the provided requirement. The evaluation employs a binary classification framework, and results are summarized through confusion matrix analysis, performance metrics, and a precision–recall trade-off visualization.
Introduction
Many engineering applications, particularly in the aerospace sector, require rigorous validation of system requirements to ensure mission safety and reliability. In this study, we address the challenge of requirement consistency verification by leveraging state-of-the-art LLMs. The synthetic dataset consists of 50 requirements distributed evenly across five subsystems of a fictional spacecraft. For each requirement, four documents—two reflecting consistent requirement interpretation and two depicting inconsistencies—were developed to mimic real-world validation challenges.
This work is motivated by the need for scalable and automated methods to support engineering validation in engineering projects. The methodology described herein not only benchmarks the performance of various LLM architectures but also provides insights into the trade-offs between precision and recall, which are crucial in high-stakes engineering environments.
Methodology
Dataset Construction
The dataset comprises 50 unique requirements evenly distributed across five spacecraft subsystems. Each requirement was paired with four synthetic documents:
- Consistent Cases: Two documents consistent with the requirement.
- Inconsistent Cases: Two documents inconsistent with the requirement.
This resulted in 200 total test cases (100 consistent and 100 inconsistent) generated using the GPT-4.5-preview model, a model not evaluated in this study.
Language Models Evaluated
Five LLMs were tested, spanning different parameter sizes and architectures:
- gemini-2.0-flash
- llama-3.1-8b-instant
- llama-3.3-70b-versatile
- gpt-4o-mini
- o3-mini
Prompting Strategy
The following standardized prompt was used without additional tuning:
Analyze the consistency between the provided Requirement and Document delineated by |||. Determine explicitly if the Document contains any information that contradicts, violates, or is inconsistent with the Requirement. Requirement: |||{REQ}||| Document: |||{DOC}||| Is the Document inconsistent with the Requirement? Provide only a direct and definitive answer with "Yes" or "No".Grading Paradigm
Responses were parsed to isolate definitive "Yes" or "No" answers. Any ambiguous responses containing both "Yes" and "No" were marked incorrect.
Results
The experimental setup mirrors a structured approach which could be taken in an engineering setting, where the trade off between minimizing false positives (having high precision) versus minimizing false negatives (having high recall) can have significant downstream implications.
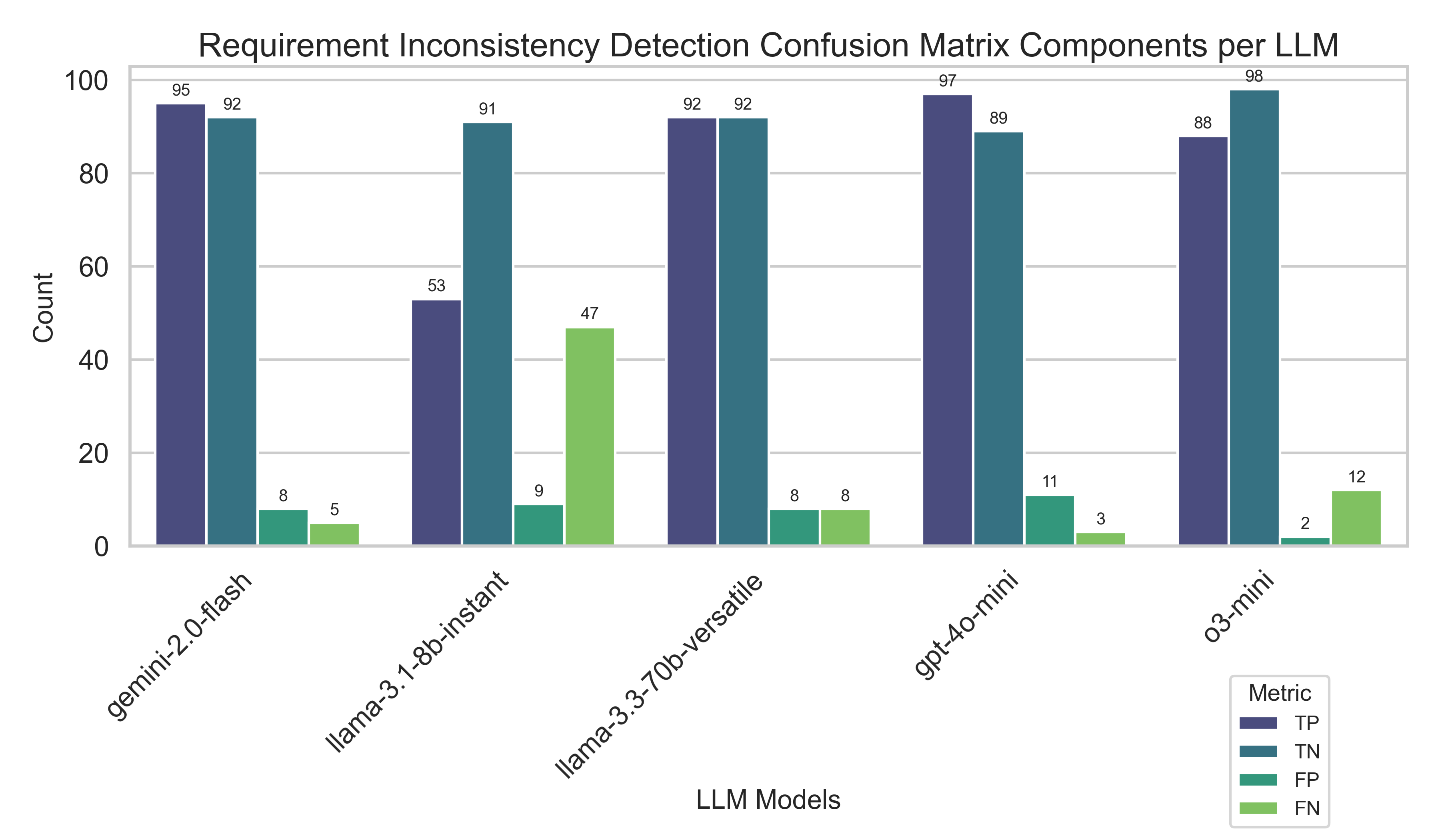
The evaluation of LLM performance in identifying inconsistencies revealed significant differences among the tested models. Figure 1 (Confusion Matrix Components) illustrates the distribution of true positives, false positives, true negatives, and false negatives for each model, providing foundational context for further analysis.
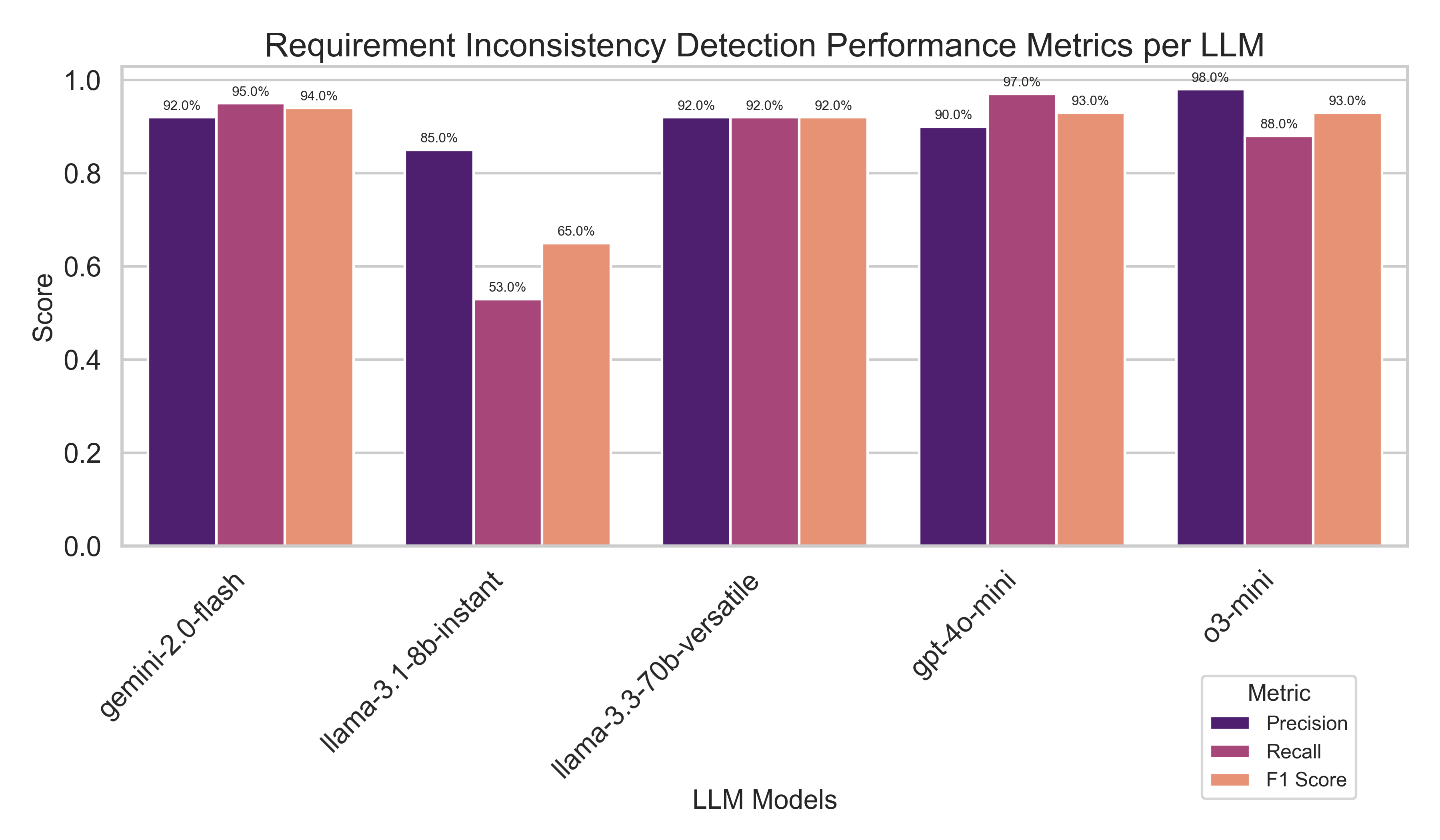
Gemini-2.0-flash achieved balanced performance with a precision of 0.92, recall of 0.95, and an F1 score of 0.94, making it suitable for scenarios demanding reliable overall performance.
Llama-3.1-8b-instant struggled notably in identifying inconsistencies, with a lower recall of 0.53. Despite its higher precision of 0.85, the resulting F1 score was only 0.65, indicating substantial room for improvement.
Llama-3.3-70b-versatile maintained equilibrium between precision and recall, each at 0.92, resulting in an F1 score of 0.92. This balanced performance positions it as a robust general-purpose option.
GPT-4o-mini demonstrated the highest recall at 0.97, essential in high-stakes aerospace contexts where missing an inconsistent requirement (false negative) can have severe consequences. However, this high recall was accompanied by a slightly lower precision of 0.90, still resulting in a strong F1 score of 0.93.
In contrast, O3-mini excelled in precision at 0.98, ideal for situations where false positives carry significant costs. However, its recall of 0.88 indicates that it may miss important inconsistencies more frequently, leading to an F1 score of 0.93.
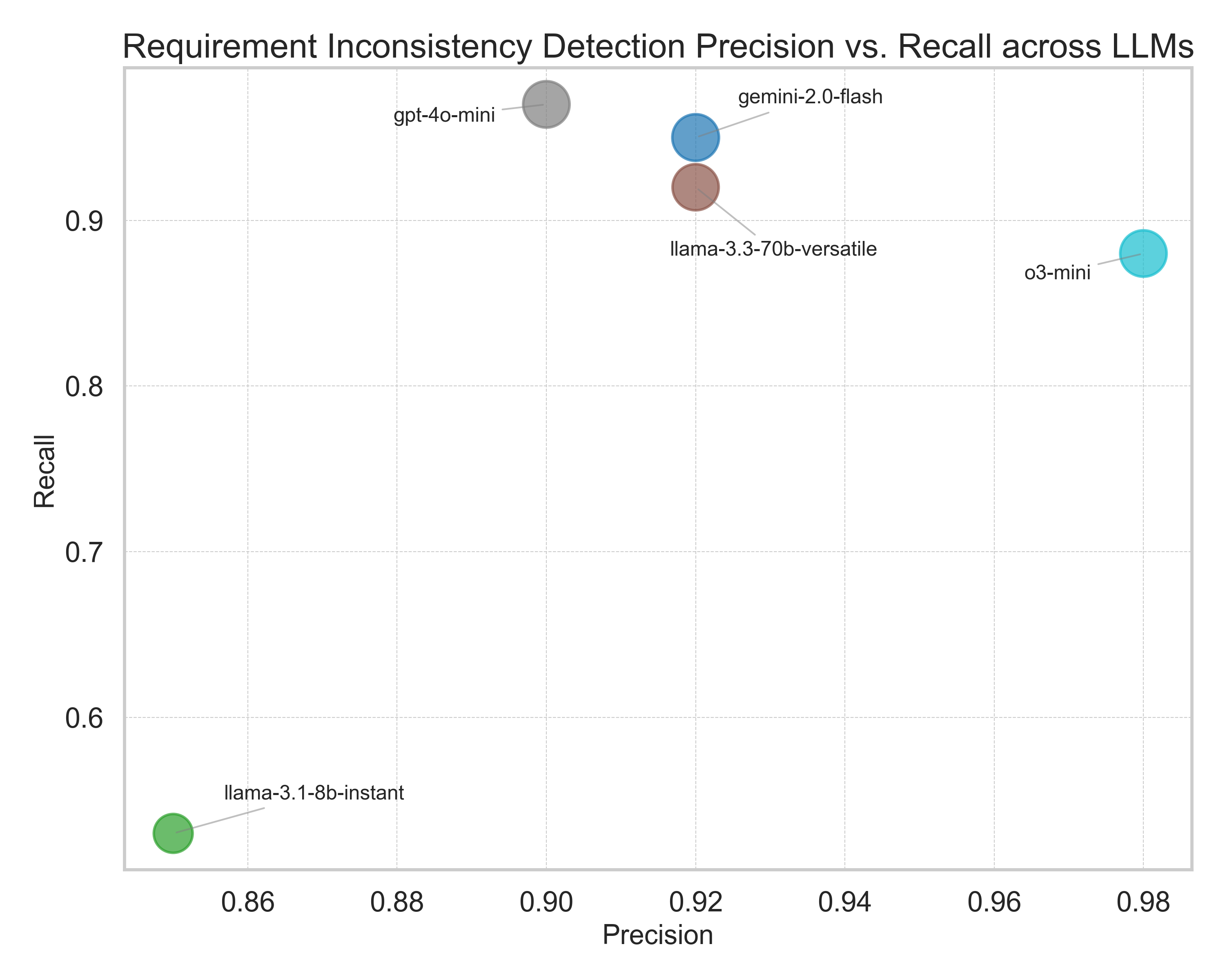
The precision–recall visualization (Figure 3) emphasizes the inherent trade-off these models face—balancing the avoidance of false positives with the comprehensive detection of inconsistencies. Given the typical "needle in a haystack" nature of requirement inconsistencies, minimizing false negatives is crucial. Models with higher recall, such as GPT-4o-mini, thus offer distinct advantages despite potentially generating more false positives. Nevertheless, the existing rates of false positives across all models indicate potential for considerable noise, suggesting significant room for improvement.
Conclusion
This study highlights both the potential and limitations of LLMs in automating the evaluation of spacecraft engineering requirements. While certain models excel under specific performance criteria, a balanced approach—as exemplified by Gemini-2.0-flash and Llama-3.3-70b-versatile—may offer the most pragmatic solution for aerospace applications. However, given the likely significantly lower rate of inconsistencies as compared to consistencies, even the best-performing models generate considerable noise due to false positives rates comparable to false negative rates. Additionally, smaller models parameter size models do not seem to perform well at the proposed task. Ideally, future efforts should prioritize reducing both false positives and false negatives. Future research will focus on advanced prompt engineering and fine-tuning strategies to enhance precision and recall, aligning more closely with the rigorous demands of aerospace validation standards.